How to build a Scalable Open Source Data Platform - Sopht - New Architecture
Sopht Data Platform Implementation - New Architecture
Published on : April 9, 2025
| Lastly edited on : April 9, 2025
| 10 minutes read

Lirav DUVSHANI
Series : How to build a Scalable Open Source Data Platform - Sopht - Project Plan
Sopht Data Platform Implementation - Project Plan
Sopht Data Platform Implementation - New Architecture
Kestra's success story at Sopht
How to ensure quality in the development of data pipelines
How to empower data stewards with a dedicated data quality reporting
Project Details
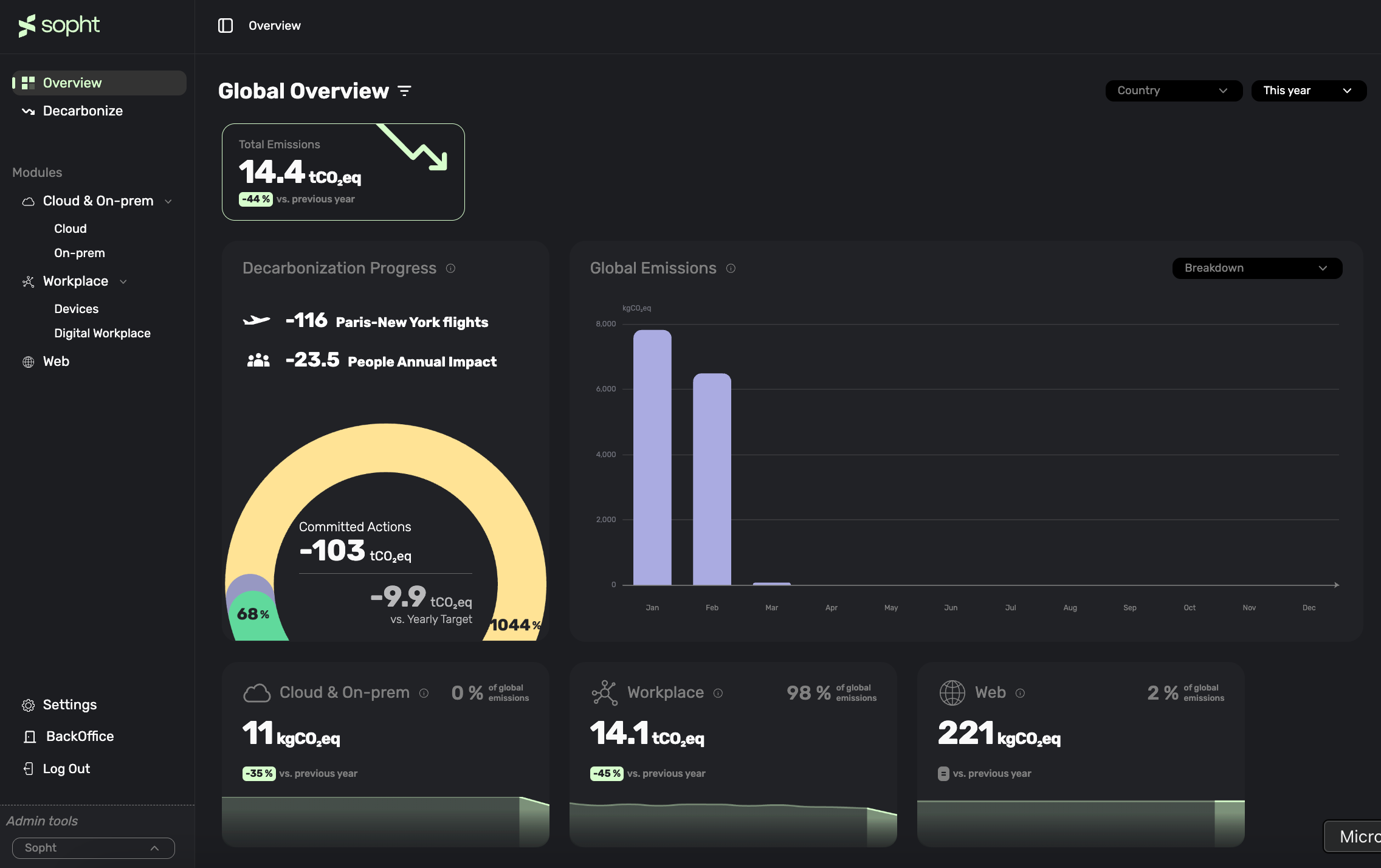
Sopht - A Green ITOps Solution

Sopht is a French start-up building a unique Green ITOps data-driven solution to lead environmental and financial performance with automated decarbonization recommendations & guided actionability. Here's how the solution works :
- Automated data collection : Automated and streamlined data collection across the entire IT value chain covering SaaS, hardware, usage, Cloud & On-Prem, networks, web, and more.
- Granular & dynamic analysis : Real-time analysis of Scope 2 and 3 emissions with methodology based on LCA, GHG Protocol, ADEME, ISO...
- Suggestions & simulations : Recommendations from the solution and simulation of the impact of the decarbonization levers.
- Distributed steering : Capacity to build, assign and track actions plans and closely monitor the real-time impact of these actions on the decarbonization trajectory.
As you can imagine, Data is at the core of the software provided by Sopht.
Context
At the start of 2024, after a successful seed round, Sopht needed to ensure the scalability of their solution to ensure both the increase in the customer base (increase in number of customers) but also in the features provided to customers.
In this context, we audited the current state of the software architecture, mainly its data architecture and proposed a target architecture including key improvements. Our evaluation identified potential bottlenecks, inefficiencies, and areas for optimization to enhance scalability and performance.
Based on our findings, we provided strategic recommendations to align the architecture to the future business and technical needs.
The Sopht initial calculation core module
At the heart of Sopht, there is a calculation module which has all the standard features of a data platform : data collection, transformation and monitoring.
The calculation "core" module was built as a monolyte for the entirety of the transformation (cleaning, modelisation, transformation, preparation for reporting).
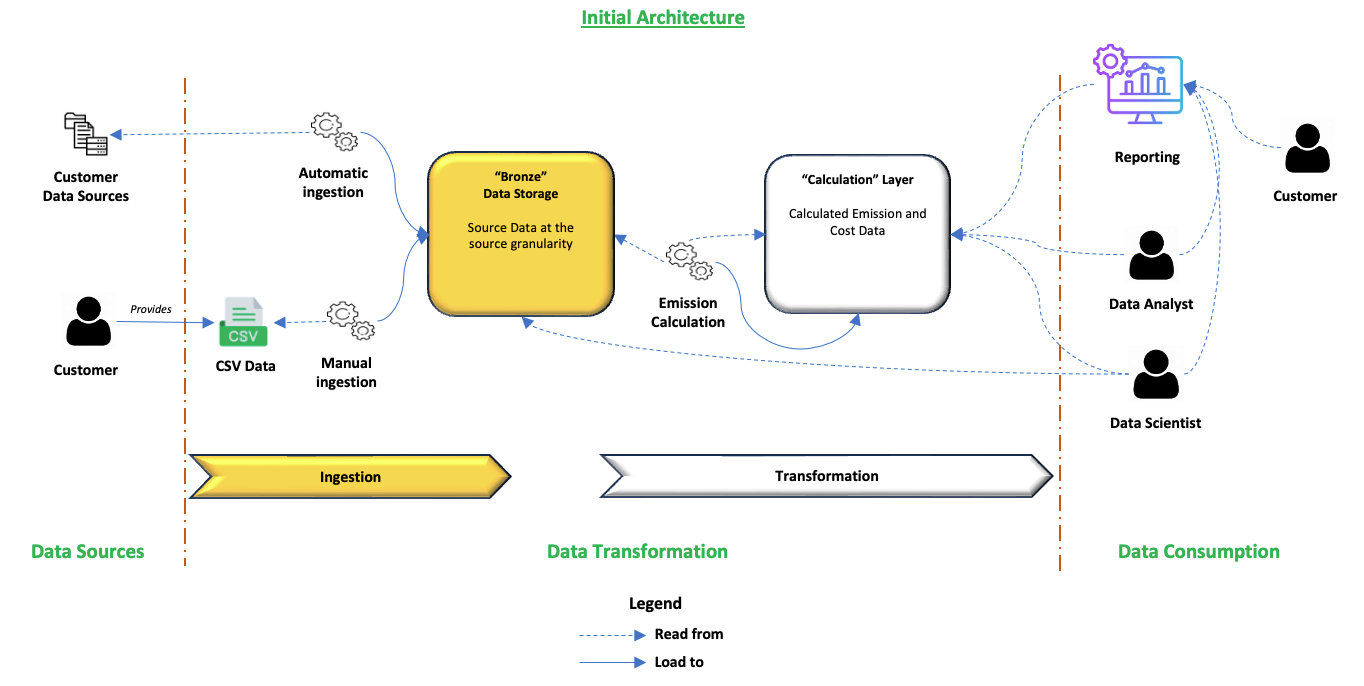
Tools of this initial version
The initial build of the calculation "core" module was created using :
- MongoDB for data storage
- PostgreSQL for data storage and compute of calculation
- Kotlin for customer data collection (Bronze layer)
- Python for data processing in the calculation layer
- Angular for the Front End plugged to the PostgreSQL database
- Docker for application packaging
- Kubernetes Cosmos on Scaleway for container orchestration
- Terraform for automating and managing the cloud infrastructure
- Git for the SCM of the data pipelines and CI/CD process definition
- Flyway for the deployment of PostgreSQL
The limitation of this version
| Theme | Limitation |
|---|---|
| Monitoring | No dedicated scheduling tool was implemented, making the monitoring of the data pipelines very complex |
| Development | No standard structure of code was defined, creating complexity on the readability of the code and its maintenance |
| Scalability | Many performance issues were present due to entanglement of data flow loading Activating new customers was also complex, as no independent process was available. |
| Testing | No standard for unit testing was implemented, leaving tests solely to the Product team during functional testing Only 2 environments available : Dev and Production, where only production had customer data, which implied many features to be tested directly in Production |
| Architecture | Data Cleaning, Business rules and internal parametrization were all done in the same layer without clear standard |
| Root Cause Analysis | Root cause analysis was highly complex due to the lack of a standardized architecture |
As the most important part of the value proposition of Sopht, a more robust scalable calculation module was to be built, to enable the expected increase in customers and features
A new scalable Data Platform but not only that...
The audit of the initial version revealed some of the pain points of the architecture and a new Data Platform was to be designed.
This new platform was to take into account the scalability and stability part as well as many other requirements presented below :
- Stability of the platform : Ensure the reliability of the data process, minimizing downtime and disruptions
- Scalability of the platform : Accommodate increase in data volume, in data compute needs without compromising performances
- Usage of well-known and tested tools : Enhance the reliability and maintainability of the tools used, to limit the risks and simplify integration
- Leveraging open-source whenever possible : Prioritize open-source technologies for their flexibility, strong community support and cost efficiency, also reducing dependency on proprietary vendors
- Implementation of a data governance : Empower internal data stewards and define clear responsibilities upon the data
- Anticipate the changes and communicate them : Provide the possibility to anticipate all changes done and communicate to customers with confidence
- Standardisation of data pipeline development and architecture : Facilitate design, implementation and maintenance of data pipelines, reducing technical debt and accelerating development.
- Implementation of best practices : Define standard naming conventions and clear separation between each data processing layer
- Have customer specific scopes : Ensure the independence of each customer data and flow execution
- Ensure the correctness of the data calculated : Ensure the extensive testing of the solution; through unit testing and functional testing
- Enable data integration for structure and semi-structured data : Provide the adequate flexibility to the data platform to enable different types of format enabled in the data integration
The proposed Data Architecture
Due to the complexity of the different steps, having a single place where every data process occurred didn't match the requirements of flexibility, stability and scalability.
A medallion style architecture was proposed to ensure a clear structuring of the project, efficiency in development and root cause analysis, as well as reliability.
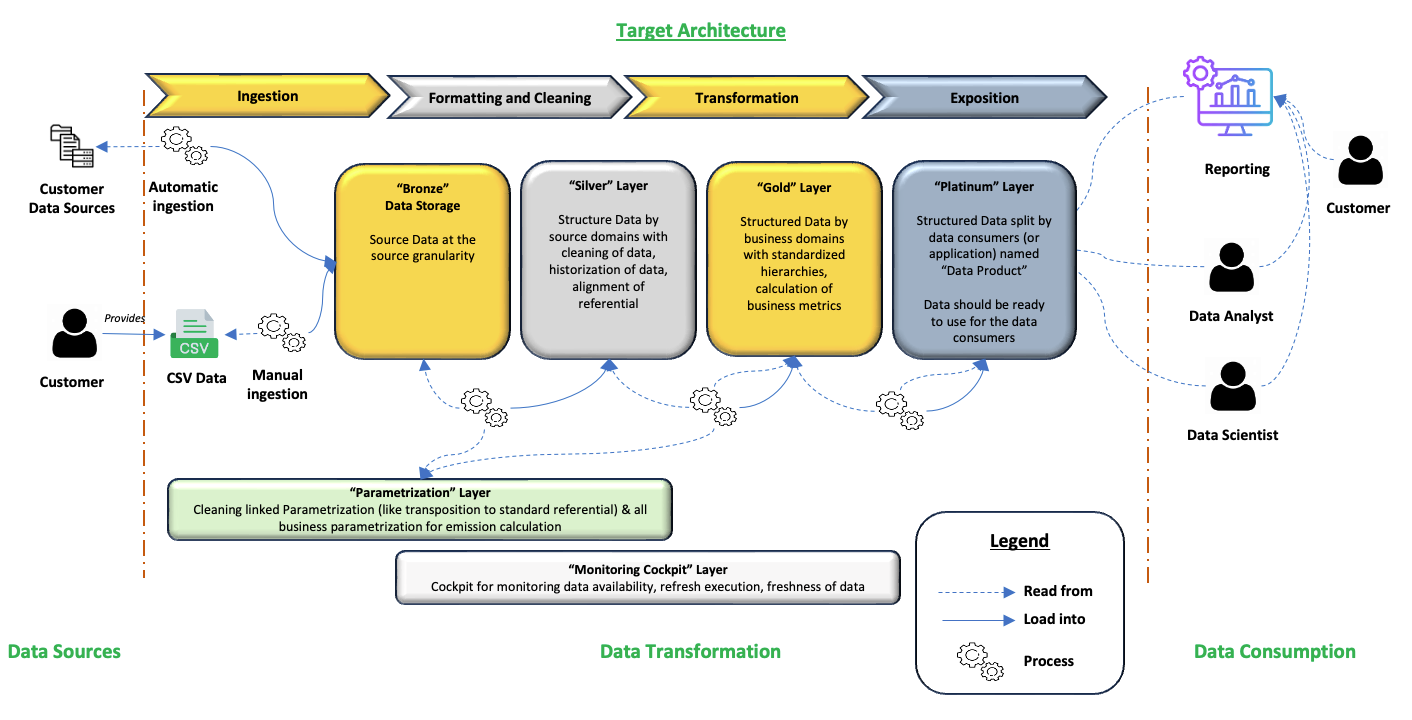
The purpose of each layers is available in the dedicated architecture post.
The tools of the proposed Data Architecture
In this new data architecture, the tools proposed were (in bold the changes) :
- S3 for data storage in the bronze and silver layer, using Parquet files
- PostgreSQL for data storage and compute of calculation in the gold and platinum layer
- Kotlin for customer data collection (Bronze layer)
- Python and DuckDB for data processing in all layers, except Bronze (New Standard Framework for data processing in both Python and DuckDB)
- Angular for the Front End plugged to the PostgreSQL database
- Docker for application packaging
- Kubernetes Cosmos on Scaleway for container orchestration
- Terraform for automating and managing the cloud infrastructure (Changes to the deployments to be customer specific)
- Kestra for orchestration and monitoring
- Git for the SCM of the data pipelines and CI/CD process definition
- Git for parametrization layer containing all the business internal parametrization
- Flyway for the deployment of PostgreSQL
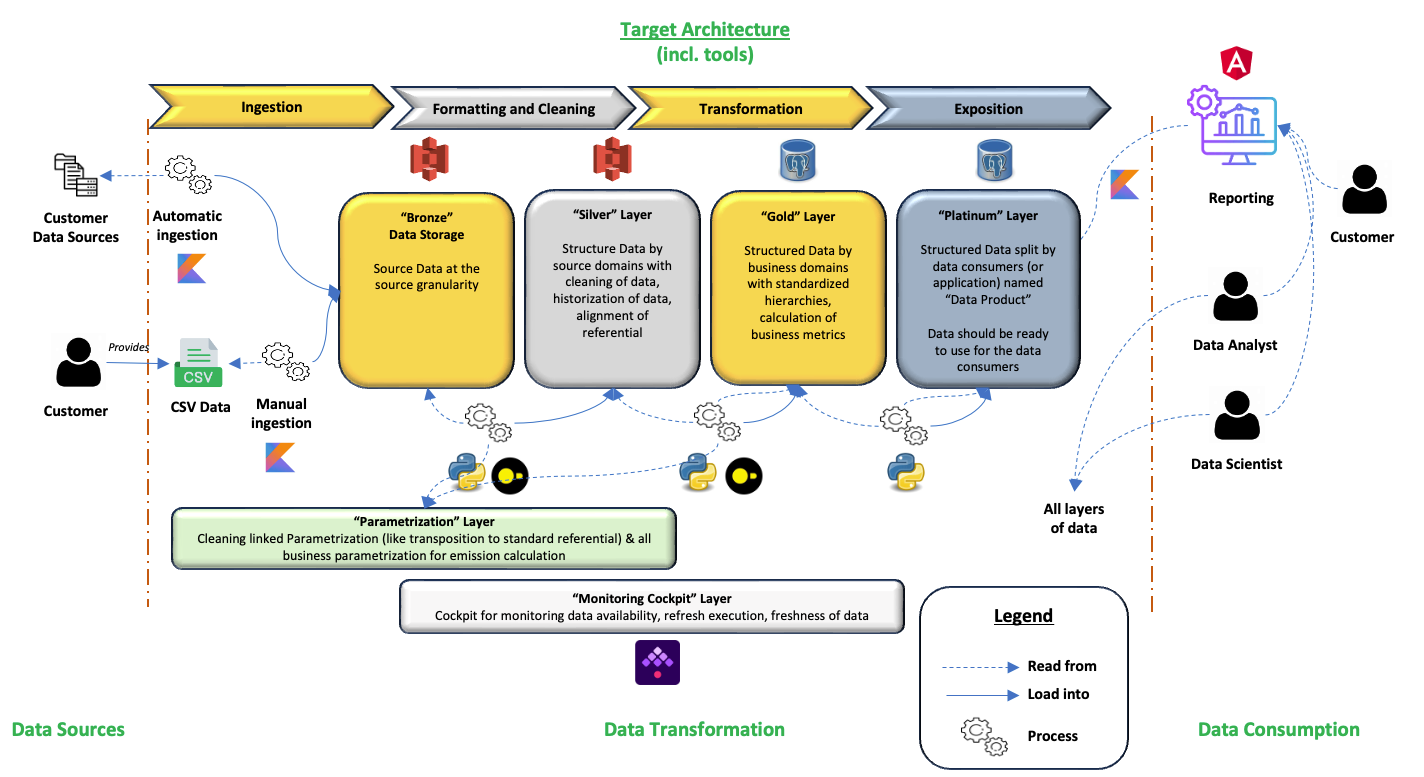
Dedicated articles will be available in the near future to detail the choice of these tools.
What about the data features lifecycle ?
A new strategy for environments was designed to maintain stability while allowing for flexible development.
The target proposed includes 3 environments : Development, Staging and Production. Each with a different purpose :
- Development : Sandbox intended for developers to build, test and iterate on features
- Staging : Pre-production environment that closely mirrors production, used for testing of new features and bug correction
- Prod : Customer facing environment with all the validated features
Here is a detailed list of features for each environment:
| Feature | Dev | Staging | Prod |
|---|---|---|---|
| Code Development | ✅ Yes | ❌ No | ❌ No |
| Testing (Unit) | ✅ Yes | ❌ No | ❌ No |
| Testing (Performance) | ❌ No | ✅ Yes | ❌ No |
| Testing (Non-regression) | ❌ No | ✅ Yes | ❌ No |
| Testing (Functional) | ❌ No | ✅ Yes | ❌ No |
| Data | Partial | Complete | Complete |
| Automatic Scheduling | ❌ No | ✅ Yes | ✅ Yes |
| Customer facing | ❌ No | ❌ No | ✅ Yes |
This article is part of a series showcasing the design and implementation of a scalable open source Data Platform for Sopht, a French Green ITOps start-up.