Data Pipeline Unit Testing with Pytest at Sopht
How to ensure quality in the development of data pipelines
Published on : May 20, 2025
| Lastly edited on : May 20, 2025
| 7 minutes read

Lirav DUVSHANI
Series : How to build a Scalable Open Source Data Platform - Sopht - Project Plan
Sopht Data Platform Implementation - Project Plan
Sopht Data Platform Implementation - New Architecture
Kestra's success story at Sopht
How to ensure quality in the development of data pipelines
How to empower data stewards with a dedicated data quality reporting
About Sopht

Sopht is a French start-up building a unique Green ITOps data-driven solution to lead environmental and financial performance with automated decarbonization recommendations & guided actionability.
The context
Sopht was designing a new data architecture to ensure the scalability of their data platform. To know more about the complete project, you can have a look at our dedicated article.
One of the identified pain points during the audit was the difficulty to add new features without regression, thus the need of easy unit testing for the entire data platform arose.
The silent damage of inaccurate data
When providing data to users, one of the main challenges for the data team is that the data needs to be correct, aligned with business logic and the source data. Obviously, you can have the best visuals, but if your data is not correct, it is pointless.
What can happen ?
- Sometimes, the figures are so unrealistic that business users themselves report the error — and that’s often how the issue gets discovered.
- Other times, the problems are minor and go completely unnoticed.
- A change made to one part of a rule can unexpectedly affect other parts that shouldn’t be impacted — leading to side effects that are hard to predict.
All these issues decrease the trust from users on your data application, it makes it seem even not that professional. Basically, you decrease the impact that you could have.
All these issues gradually erode users’ trust in your data application. It starts to feel unreliable, even unprofessional. In the end, you’re not just introducing bugs — you’re undermining the impact your product could have.
How unit testing can help improve data accuracy ?
When building a data application, it’s often easy to run tests on full datasets or even PROD-like environments. But these tests rarely target specific edge cases or business rule nuances.
This is where unit testing becomes essential. It allows developers to test individual data pipelines in isolation, using controlled input datasets designed for specific scenarios.
The goal? To ensure each part of your pipeline produces the expected result given a known input — without being affected by external dependencies.
Although testing simple data pipeline might seem overkill, any unit test applied to data pipeline with transformation like cleaning, aggregation, filtering or even complex rules enables clear validation of the feature.
By testing these pieces in isolation, you validate the logic itself, not just the final dashboard.
The unit testing standard process consists of 3 steps :
- Load source data, configured as part of the unit test, into the source structure
- Execute the process to test
- Compare the result of the process with the expected result
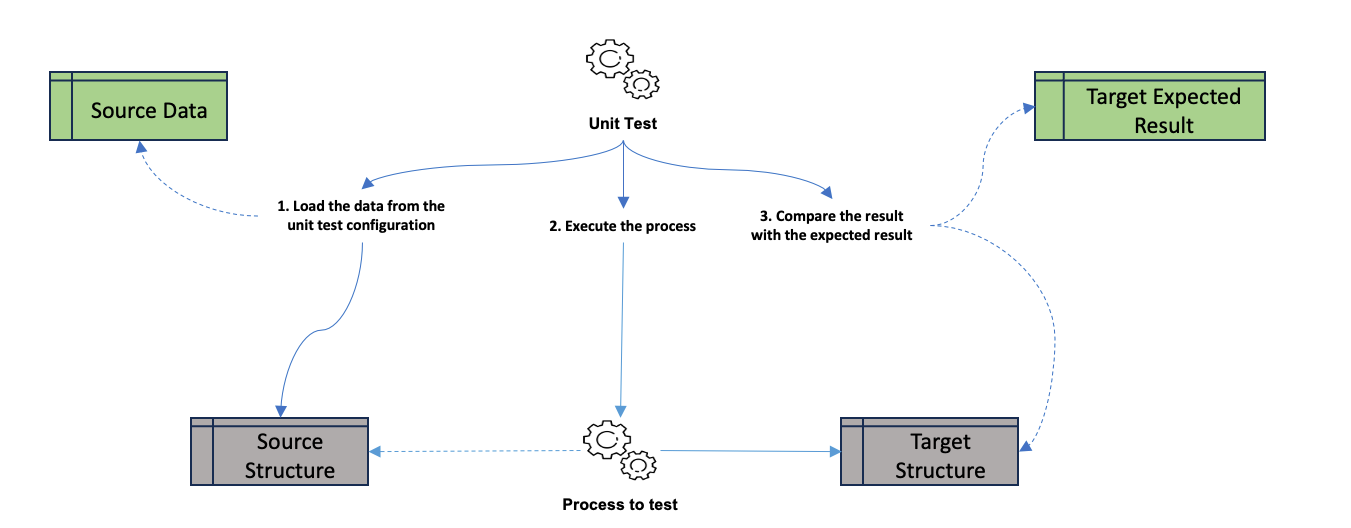
This approach encourages a test-driven development mindset — helping your team catch regressions early, build trust in the data logic, and ultimately, deliver more accurate and reliable data products.
How was implemented data pipeline unit test using pytest ?
An example with PostgreSQL
As all the data pipelines of the project were developed from the python project, pytest was chosen as the tool for executing the unit tests.
To enable unit testing, the tests need to have all the components up-to-date in a similar way as expected in the code. So any database used should be available to enable the
To ensure all tests have the correct infrastructure, at the start of the pytest execution, the PostgreSQL database and all structures inside them are created.
Then the different unit tests can use this fixture to know the connection to the PostGreSQL databases.
This is done using the conftest.py file with a code similar to this, using the psycopg2 library.
from psycopg2 import pool
from psycopg2.pool import SimpleConnectionPool
@pytest.fixture(scope="session", autouse=True)
def postgresql(request: Any) -> Generator[SimpleConnectionPool, Any, Any]:
# Creation of the PostgreSQL container
# Execution of flyway container to execute all the structure scripts
# Yield a Postgresql simple connection pool for the PostgreSQL container created for this test
yield pool.SimpleConnectionPool(postgresql_credentials)
# Stop the PostgreSQL container
This fixture can then be reused in all the unit tests
from psycopg2.pool import SimpleConnectionPool
@pytest.fixture(scope="function", autouse=True)
def setup_and_teardown_data(
postgresql_pool: SimpleConnectionPool,
) -> Generator[Any, Any, None]:
# Load the input data of this unit test
# Specific to each unit test
yield
# Remove all the data from the database
# Specific to each unit test
def test_data_pipeline(postgresql_pool: SimpleConnectionPool) -> None
# Execute the process
# Retrieve the expected result data
# Compare the expected result data from the actual result data
Each unit test is structured in a similar way, as presented below, with a single example containing 2 source files and 1 target file.
- database
- conf ➡️ Contains the configuration for the test postgresql database
- migrations ➡️ Contains the complete migration scripts for PostgreSQL database
- lib
- data_pipelines
- data_pipeline_1.py ➡️ Data Pipeline #1
- data_pipelines
- tests
- conftest.py ➡️ Contains the initialization of the postgresql database inside the docker container
- data_pipelines
- data_pipeline_1_test.py ➡️ Contains all the test of process Data Pipeline #1
- data_pipeline_1_test_files
- {structure_name_1}_source.csv ➡️ Source Data for structure #1 used in process Data Pipeline #1
- {structure_name_2}_source.csv ➡️ Source Data for structure #2 used in process Data Pipeline #1
- {structure_name_3}_result.csv ➡️ Expected Data for structure #3 used in process Data Pipeline #1
- pytest.ini
The complete example is available in the GitHub Repository
How did this impact the Sopht organisation and process ?
To ensure quality over the entire data pipelines, a key practice was to make unit testing mandatory. A development task was only considered complete once its corresponding unit were written, reviewed, and validated — just like the main code itself.
By end of 2024, the team had implemented 205 unit tests, covering approximately 91% of the python codebase.
This level of coverage significantly reduced the risk of regressions, especially in complex transformation logic.
Beyond the numbers, the adoption of unit testing had a transformational impact on the team’s development culture:
- It improved code robustness, by forcing developers to think about edge cases and data consistency from the start
- It improved collaboration, as tests served as living documentation of business rules
- And above all, it improved confidence — both for the developers and for stakeholders relying on the data
Unit testing became one of the most critical drivers of quality in the data team's delivery process.
This article is part of a series showcasing the design and implementation of a scalable open source Data Platform for Sopht, a French Green ITOps start-up.