Kestra, the appropriate tool for a scalable data platform - Sopht
Kestra's success story at Sopht
Published on : April 22, 2025
| Lastly edited on : April 22, 2025
| 8 minutes read

Lirav DUVSHANI
Series : How to build a Scalable Open Source Data Platform - Sopht - Project Plan
Sopht Data Platform Implementation - Project Plan
Sopht Data Platform Implementation - New Architecture
Kestra's success story at Sopht
How to ensure quality in the development of data pipelines
How to empower data stewards with a dedicated data quality reporting
How Kestra met the needs of the scalable Data Platform at Sopht
About Sopht

Sopht is a French start-up building a unique Green ITOps data-driven solution to lead environmental and financial performance with automated decarbonization recommendations & guided actionability.
The context
Sopht was designing a new data architecture to ensure the scalability of their data platform. To know more about the complete project, you can have a look at our dedicated article.
On the initial version of the data architecture, most of the jobs were run via cron job, but this simply could not scale.
So during the design phase of the new version of the data architecture of Sopht, one of the elements that needed to be added was an orchestrator.
If you want to know more about why orchestration tools are so important in data architecture, you can have a look at our dedicated article on the topic.
Why was Kestra chosen as the orchestrator ?
On the market, there are many different orchestrators and the market is very competitive.
The data pipelines were to be coded in various languages, but mostly in Python and Kotlin. As there needed to be a flexibility on the languages due to different languages being used, the preferred direction was to find a tool that enables execution of Kubernetes Pod using a Docker Image.
Considering this, we looked into all the other requirements that we would need :
- Open-source solution : The tool should be freely available, with an active community for support and contributions
- Scalability and performance : The tool should handle large-scale workflows with minimal performance degradation
- Parallelism and concurrency : The tool should provide efficient execution of multiple tasks simultaneously without bottlenecks
- Easy adoption and usage : The tool should have clear documentation, an intuitive UI, and simple configuration
- Independent DAGs for each of the customer : The tool should provide customer independence to ensure issues within one customer's workflow do not impact others.
- Easy enablement/disablement of part of the complete DAG depending on the customer : The tool should provide flexibility to configure customer's workflows based on their available data sources.
- Event-based triggering between tasks : The tool should enable event based triggering to enable real-time orchestration
Looking at all these expected features, Kestra met all the requirements with their open-source declarative approach to orchestration and the high interoperability between Kestra and Terraform which could be used to create specific DAGs for each of the customers.
An added bonus was that Kestra was part of the same ecosystem as Sopht, both being backed by the same VC Axeleo.
How was this implemented ?
All the data pipelines were developed in the Kestra declarative approach to execute Kubernetes Pods for the load of all the layers : Bronze, Silver, Gold and Platinum.
The Kestra project was build with 2 different folders :
- First, the complete DAG, with all the data sources and data pipelines
- Secondly, the customer specific DAG, where only the customer data sources are activated
The configuration of a customer was built to be managed using terraform with the addition of a new kestra_flow resource in terraform, where the data sources specific to the customer were activated.
To give you an idea of the implementation, here is a sample of a terraform kestra_flow resource for a customer named customer_1 :
resource "kestra_flow" "customer_1" {
for_each = fileset("${path.module}/flows/tenant", "*/*.yaml.tftpl")
namespace = format("customer_1.%s", split("/", each.key)[0])
flow_id = split(".", split("/", each.key)[1])[0]
content = templatefile("${path.module}/flows/tenant/${each.key}", {
sopht_environment = var.sopht_environment
tenant_code = "customer_1"
src_cloud_aws = 1
src_cloud_gcp = 1
src_cloud_azure = 1
src_cloud_oci = 0
default_schedule = "30 0 * * *"
})
}
How did we measure the success ?
First of all, having an orchestration tool revolutionized the way data pipelines were handled. With a quick glance every morning, the Tech team could check what issues had been encountered during the nightly runs.
More specifically, the orchestration tool provided :
- Reliability in processes : With the handling of task failures
- Visibility and transparency: With a clear view on each customer data pipeline executions
- Monitoring: With all logs available in the Kestra UI
- Facilitated activation of a customer : With a simple activation through terraform configuration
This impacted the tech team with the :
- Reduction of time spent on manual tasks
- No more time spent manually checking logs
- No more manual triggers on tasks
- Simple activation of a new customer
- Identification of tasks to optimize
- The added ability to know task individual performance, which facilitated the identification of tasks with performance issues
- Increase in the efficiency on new developments
- Addition of a data pipeline was made a lot easier
Some KPIs about Kestra usage
- Number of Daily Kestra jobs :
- 1 240 in the first weeks after the go-live (end of October 2024)
- 6 200 about 6 months after the go-live, with additional customers activated and additional features (data pipelines) added
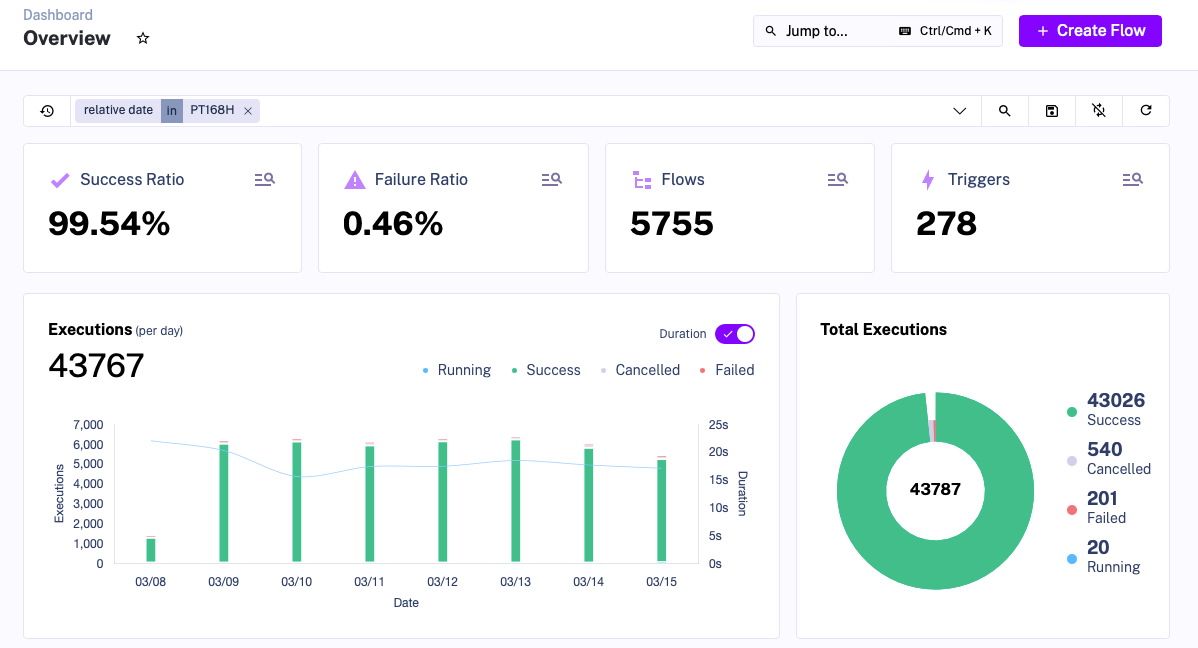
- Average Kestra job Success Rate :
- 98,12% in the first weeks after the go-live
- 99,54% about 6 months after the initial go-live
This article is part of a series showcasing the design and implementation of a scalable open source Data Platform for Sopht, a French Green ITOps start-up.